I Stopped Coding for 11 Weeks — and Still Placed 3rd on Kaggle
I stopped writing code in January and used Claude Code as my sole development tool for a Kaggle competition — translating 4,000-year-old Akkadian cuneiform tablets into English. My teammate Raja Biswas and I placed 3rd out of 3,000 (technical writeup).
Over those eleven weeks we exchanged 277,000 messages (10k from me, 267k agent) and 30,000 tool calls. I focused only on quality checks, specifying workflows, constraints, and decisions for an agent to carry out. Raja used Claude Code to tackle model performance head-on, analysing training dynamics, activations, and errors to squeeze out the final gains.
The Numbers (Jan 9 - Mar 21, 2026)
These numbers cover the full competition period — from first commit to final submission. However the numbers in this section do include other projects, not only Deep Past.
|
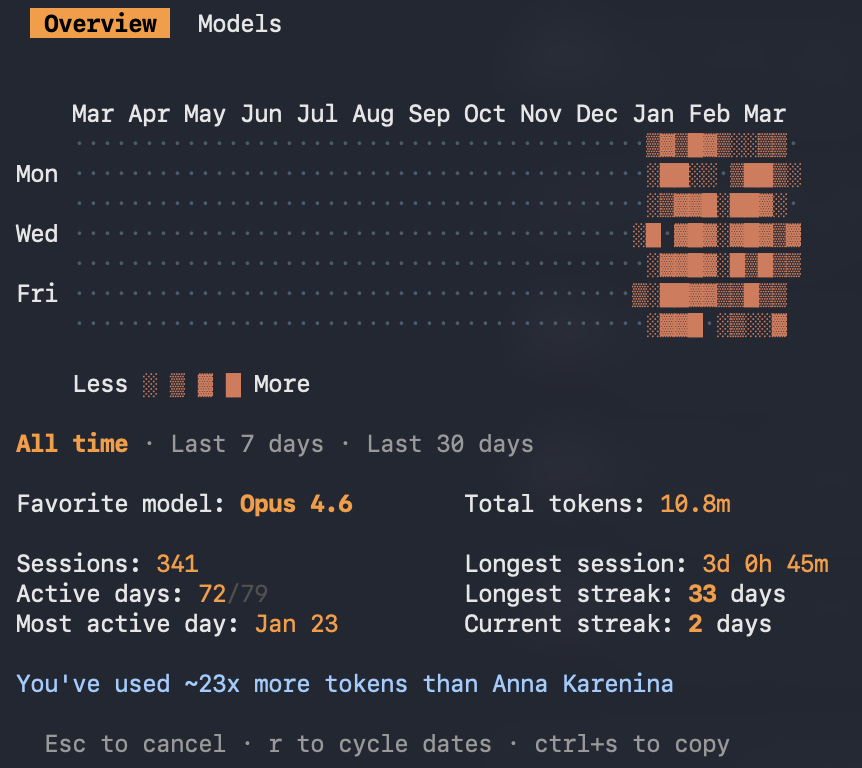
|
Some short context if you are unfamiliar with the basics of Claude Code: each session is a fresh conversation — the agent doesn't remember previous ones. What carries over are two things you build up over time: a CLAUDE.md file (a markdown file the agent reads at the start of every session — your project's rules, conventions, and a map of the codebase) and skills (reusable prompts that teach the agent multi-step workflows — like macros in English). These give the agent continuity across sessions. This sounds more complicated than it is — it becomes pretty natural after a while.
The interesting thing as I learned more, is that tool calls per day went down over time. I was getting more done with less. I averaged 92 tool calls per session across 332 sessions. The agent wasn't something I used occasionally when stuck — it was running all day, every day, as a collaborator.
| Month | Tool calls/day | Sessions | How it worked |
|---|---|---|---|
| Jan | 475 | 96 | Agent writes scripts, human reviews |
| Feb | 442 | 118 | Skills encode repeatable workflows |
| Mar | 415 | 118 | Agent designs approaches, human directs |
How My Role Changed (in Three Stages)
When I started, in January, I cloned repos, NeMo/Run, NeMo/RL, etc. to pkgs/ folder and asked Claude to create training pipelines based on this. I downloaded public kaggle scripts, and asked Claude to reproduce the numbers on my slurm environment. I monitored, spotted bugs and asked for fixes. That was Phase 1. On January 23rd I hit 1,628 tool calls and 27,819 messages in a single day. I was productive, but it was tiring.
Phase 2 started when I noticed I was repeating myself. "Blend these checkpoints, submit to SLURM, run eval, log to wandb" — I'd said it many times. So on February 3rd, I asked Claude to build 10 skills in a single session. Instead of re-explaining the blend-eval-upload pipeline every time, we defined it once and invoked it with a single command. Now, each time I think a task is repeatable, after completing the task I ask the /skill-creator to create a skill.
There was also a practical reason I stopped coding by hand. If I edited a config file or tweaked a parameter myself, I'd then have to explain the change to Claude so it could stay in sync. It was easier to just give the task to Claude — then both of us knew the change.
Phase 3 was subtler. I added MCP tools that let the agent search the web, query external APIs, and access platforms beyond my local filesystem. I started using /plan — 258 times in total — to have the agent design approaches, not just execute them. The CLAUDE.md grew from nothing to 681 lines. That file became the project's source of truth.
Here's how both the project's CLAUDE.md and the skills accumulated over time:
CLAUDE.md growth + skill creation timeline
lines
700 ┤ ● Mar 24
│
600 ┤ ● Mar 13
│ + sonar-search, get-args
500 ┤ ● Mar 7
│
400 ┤ ● Mar 1
│ + build-slides, read-host-comments
300 ┤ ● Feb 15
│
200 ┤ ● Feb 3 + ask-codex
│
100 ┤ ● Feb 1 (created)
│ + 10 skills in one session
0 ┤
└──────────────────────────────────────────────────────────
Feb 1 Mar 24
Skills as Institutional Memory
Here's something I didn't expect: the skills became as important as the model and training data.
Utility skills handle mechanical workflows. Every time I blended model checkpoints, the manual process was: select checkpoints, write a config, SSH to the cluster, submit a SLURM job, wait, download the result, run evaluation, log to wandb, download the model, create a Kaggle dataset. With two skills — /kgmon-blend-byt5 and /kgmon-upload — this became three minutes. I used them 80 and 105 times — each replacing ~10 minutes of manual work.
The more interesting category is qualitative skills — the ones that helped me think.
/kgmon-read-host-comments (41 uses) parsed a 58KB file of competition discussion posts and answered questions about rules, conventions, and edge cases. A key tweak was filtering to only the host's comments — authoritative guidance buried in competitor noise. Instead of re-reading the thread every time a formatting question came up, I'd ask "does the host say anything about determinatives?" and get an answer in seconds.
/kgmon-source-blind-test (38 uses) took samples from a new data source and had Gemini Pro evaluate them blind — no source labels, no context. When I extracted translations from a new set of Turkish academic papers, I didn't trust my own judgment on whether the quality was good enough to train on. This gave an objective opinion.
/kgmon-ask-gemini (31 uses) let me consult Gemini about Akkadian-specific questions — transliteration conventions, sign readings, whether a particular translation looked plausible. I found Gemini understood Old Assyrian very well, so I leaned on it more than Claude for domain review.
The utility skills saved hours. The qualitative skills saved me from bad decisions.
Each skill also encodes domain knowledge that would otherwise live only in my head. Ancient tablets are broken, so translations contain gap markers like <gap> where text is missing. The competition required specific marker formats — use the wrong one and the submission scores lower on that sample. The gap-check skill validates training samples against the allowed set — I'd spot-check a large batch and catch format errors in seconds. Getting the gap markers right drove our leaderboard score up 2 points into top 20 position.
What Didn't Work
I couldn't monitor training jobs. They ran on a SLURM cluster via NeMo Run. The agent could launch them fine, but it couldn't watch them — log context was too large for the agent to process.
Verification was never free. 277K messages means a lot of reading. The agent was right most of the time, but the cost of checking was never zero. My role shifted from writing pipelines to auditing them. Faster overall — but it was not effortless delegation.
The agent made confident, wrong choices. Left to its own judgment, it would pick training parameters, data sources, or preprocessing steps that looked reasonable but weren't. It would use difflib.SequenceMatcher for fuzzy matching instead of rapidfuzz — a 100x speed difference. It would assume normalization rules that broke edge cases. The agent optimized for something plausible, not something correct. The fix was tight constraints — which library to use, which data to include, what the preprocessing rules were. Without those, it drifted. My CLAUDE.md grew to 681 lines partly to preempt these: explicit instructions like "use rapidfuzz not difflib", SSH login procedures, key handling rules. The agent learned, but only because I wrote the lessons down.
Parallelization was limited. For developing and experimenting, the most I could manage was two parallel sessions. A sweet spot was research and data collection from online resources — the agent was very capable at web search and discovery.
How I Actually Talked to the Agent
The table below shows skills that I invoked — either by slash command or natural language. Behind the scenes, the agent invoked far more tools on its own: Bash, file reads, web searches, grep, git — the 30,000 tool calls in the stats table. These are just the ones I triggered directly.
I built 16 custom slash commands. But when I looked at the logs, I found something surprising: for most skills, I described what I wanted in plain English far more often than I typed the formal command.
The more thinking a skill requires, the more it was invoked via natural language — mechanical actions got the formal command. Host comments: 3 slash vs 38 natural. Upload: 70 slash vs 35 natural.
Top 10 skills used:
| Skill | Created | /slash call | Natural lang call | Total |
|---|---|---|---|---|
/plan |
built-in | 135 | 123 | 258 |
/kgmon-run-byt5 |
Feb 3 | 2 | 110 | 112 |
/kgmon-upload |
Feb 3 | 70 | 35 | 105 |
/kgmon-blend-byt5 |
Feb 3 | 61 | 19 | 80 |
/kgmon-read-host-comments |
Feb 26 | 3 | 38 | 41 |
/kgmon-source-blind-test |
Feb 3 | 12 | 26 | 38 |
/kgmon-ab-analysis |
Feb 9 | 9 | 25 | 34 |
/kgmon-ask-gemini |
Feb 3 | 4 | 27 | 31 |
/kgmon-gap-analysis |
Feb 9 | 13 | 13 | 26 |
/skill-creator |
built-in | 2 | 23 | 25 |
What I Actually Did for Eleven Weeks
I didn't write code. I decided what data to extract, which sources to trust, what quality thresholds to set, when to retrain, and what to try next. The agent could execute any of those decisions faster than I could type them — but it couldn't make them.
With limited compute, limited API credits, and a competition deadline, every decision about what to work on next mattered more than how fast the work got done. The agent made me faster. The decisions made us competitive.
As Jean-François Puget recently tweeted about this exact competition: "The era of manual competing is over on Kaggle... I don't think that the era of fully automated competing has started either. We are in an interesting middle ground for now."